
 Saxon 11 - New strings representations - Performance regressions?
Saxon 11 - New strings representations - Performance regressions?
Added by Cristian Vat almost 3 years ago
Environment: Saxon 11.1, JDK 8
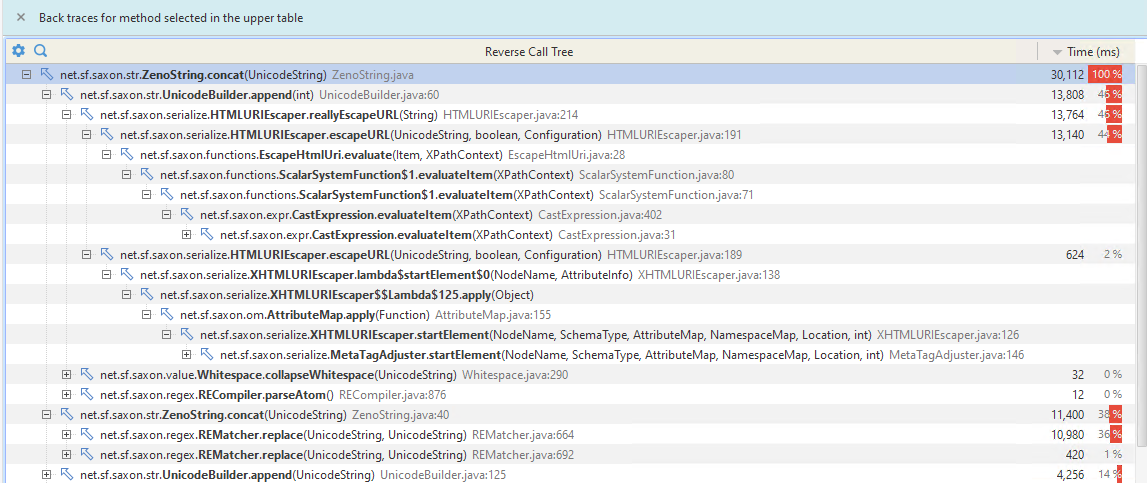
After upgrading to Saxon 11.1 I noticed some slowdown and hotspots from new methods like ZenoString.concat Attached backtraces/callees from a yourkit sampling snapshot.
The transformation had a lot of:
-
replace()function calls -
escape-html-uri()function calls - element generation with
xsl:attribute name="href"that needed escaping- so this affects serialization of all attributes matching
net.sf.saxon.serialize.HTMLURIEscaper#isUrlAttribute
- so this affects serialization of all attributes matching
I worked around my problems by offloading to a Java extension function.
The replace() calls I'm not sure about but for escape-html-uri() and associated XHTML serializer calls this seems like a regression.
- Test case: I had some URIs that were around 200 characters long but only 1 or 2 characters needed escaping.
- Up to and including Saxon 10
HTMLURIEscaper#reallyEscapeURLused anew FastStringBuffer(url.length() + 20); - In Saxon 11.1 it seems to just initialize an empty
UnicodeBuilder
HTMLURIEscaper#escapeURL is optimized for the common case of only ASCII characters so if we enter reallyEscapeURL it's clear that the resulting string will be at least the size of the input string, right?
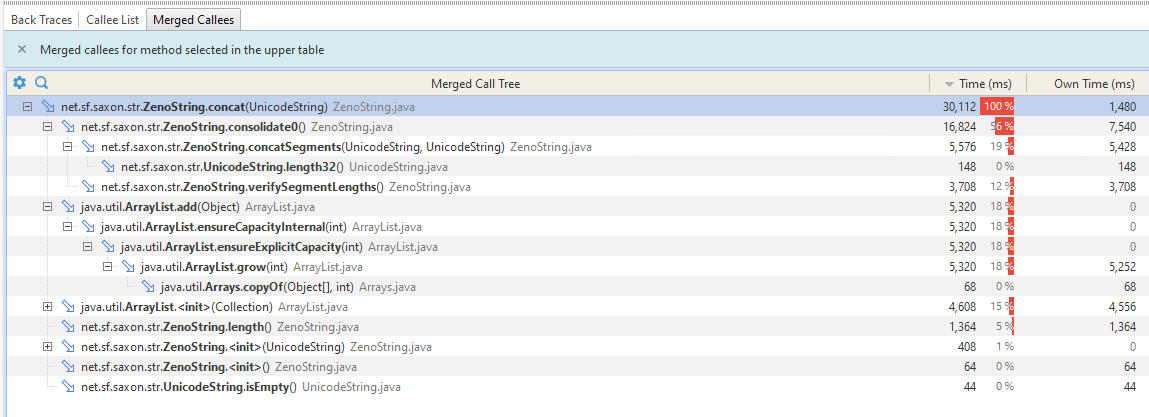
But with the new string handling we start with an empty builder and it seems a lot of time is spent in growing the ArrayLists and the consolidation.
Maybe it makes sense to specialize HTMLURIEscaper#reallyEscapeURL ? Since it had a specialized pre-allocation already in previous versions.
This was the biggest hotspot I noticed so far relating to new string handling but I'm still going through other transformations in the next days so I'll update if I find anything similar.
| saxon_11_strings_concat_backtraces.png (89.4 KB) saxon_11_strings_concat_backtraces.png | string concat backtraces | ||
| saxon_11_strings_concat_merged_callees.png (44.4 KB) saxon_11_strings_concat_merged_callees.png | string concat callees |
{kind=link}
{kind=link}
Replies (3)
Please register to reply
 RE: Saxon 11 - New strings representations - Performance regressions?
-
Added by Michael Kay almost 3 years ago
RE: Saxon 11 - New strings representations - Performance regressions?
-
Added by Michael Kay almost 3 years ago
Thanks, this is very helpful. We're aware that some paths have speeded up with the new string representation, and others have slowed down, so feedback on this will help us with the fine tuning.
RE: Saxon 11 - New strings representations - Performance regressions?
-
Added by Michael Kay almost 3 years ago
Looking at it, there are very obvious inefficiencies here in repeated conversion between String and UnicodeString. These are sometimes unavoidable, because of JDK methods like Normalizer.normalize(), but it's clearly excessive on this path.
The UnicodeBuilder is really optimised for a relatively small number of appends of long strings, and not for a case like this with a modest number of very short strings.
RE: Saxon 11 - New strings representations - Performance regressions?
-
Added by Michael Kay almost 3 years ago
I have logged issue #5297 - please follow progress there.
Please register to reply