
Bug #2929
closed
Performance regression for whitespace stripping in 9.7
100%
Description
I have started testing upgrade from 9.6.0-7 to 9.7.0-8 in our Java application.
We are using extension functions which are registered like:
processor = new Processor(false);
for (ExtensionFunctionDefinition f : extensionFunctions) {
processor.registerExtensionFunction(f);
}
In a tiny unit test, the execution time goes from 0.5s to 1.0s.
In large integration tests the execution time increases by a factor 6 (5min to 30min).
Are there any changes in 9.7 that are known to significantly slow down calls to Extension Functions? Any changes we can make related to how we register them in SaxonHE?
Files
{kind=link}
{kind=link}
 Updated by Michael Kay about 8 years ago
Updated by Michael Kay about 8 years ago
Thanks for reporting it; if you can put together a repro package that allows us to reproduce and investigate the problem then we will do so.
I can't think immediately of any reason for this. The first thing that comes to mind is that the optimizer is being more cautious about changing code that includes calls to extension functions because of the possibility that they have side-effects. Comparing the -explain output in 9.6 and 9.7 might shed some light.
 Updated by Thomas Åkesson about 8 years ago
Updated by Thomas Åkesson about 8 years ago
Thanks for responding.
Sorry, I was likely wrong about the performance regression being related to extension function. I had a set of unit tests that were misleading. I do see the compile stage taking significantly more time and I understand that there is a trade-off btw compile time and execution. I am seeing that compiling an "identity stylesheet" takes approx 400ms more time (double) in 9.7. I need to insert caching in some situations.
I will try to provide a package. Will take some time to untangle something from our dependencies or figure out exactly what we are doing that triggers the regression.
I used jvisualvm to sample a unit test that I use for performance comparisons. I will attach 2 screenshots:
-
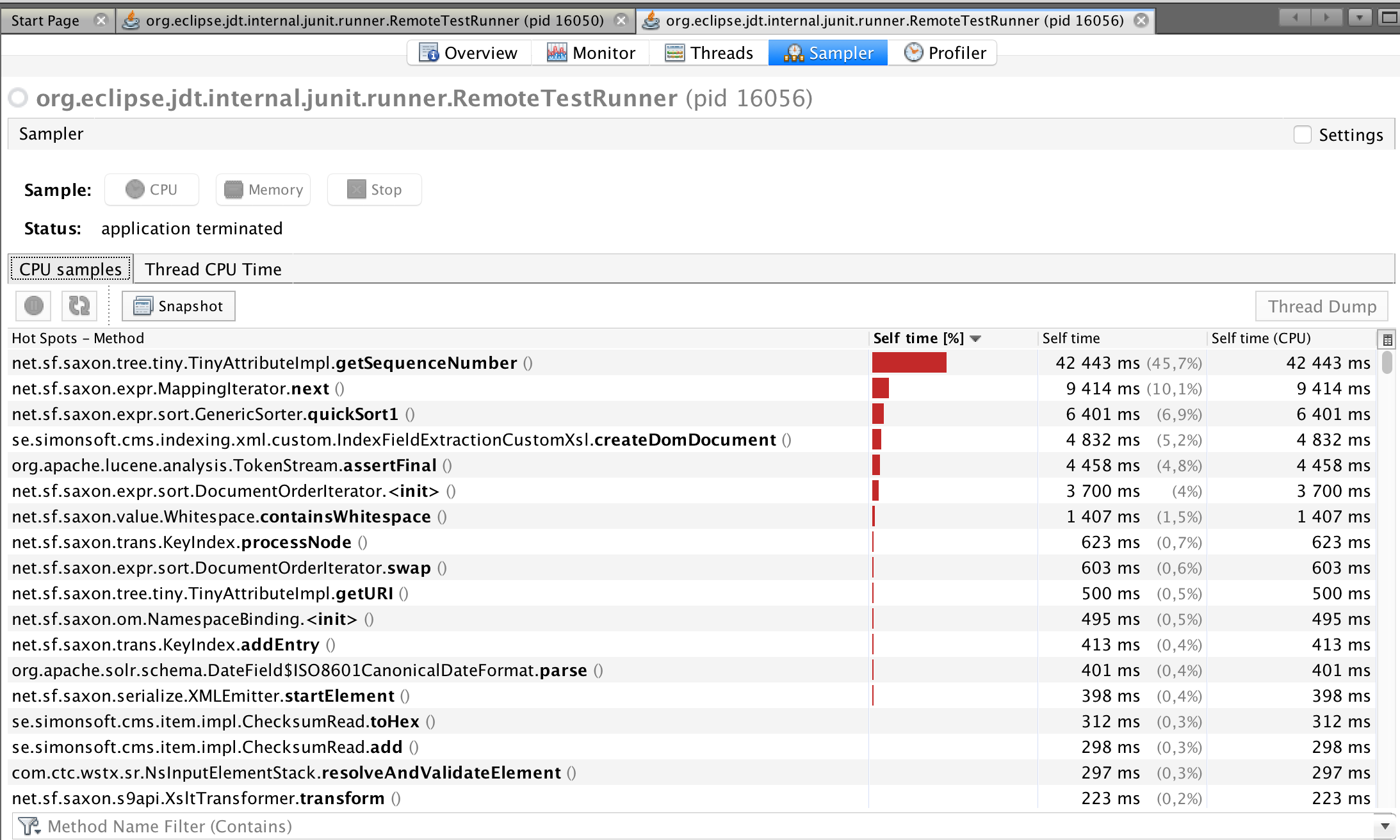
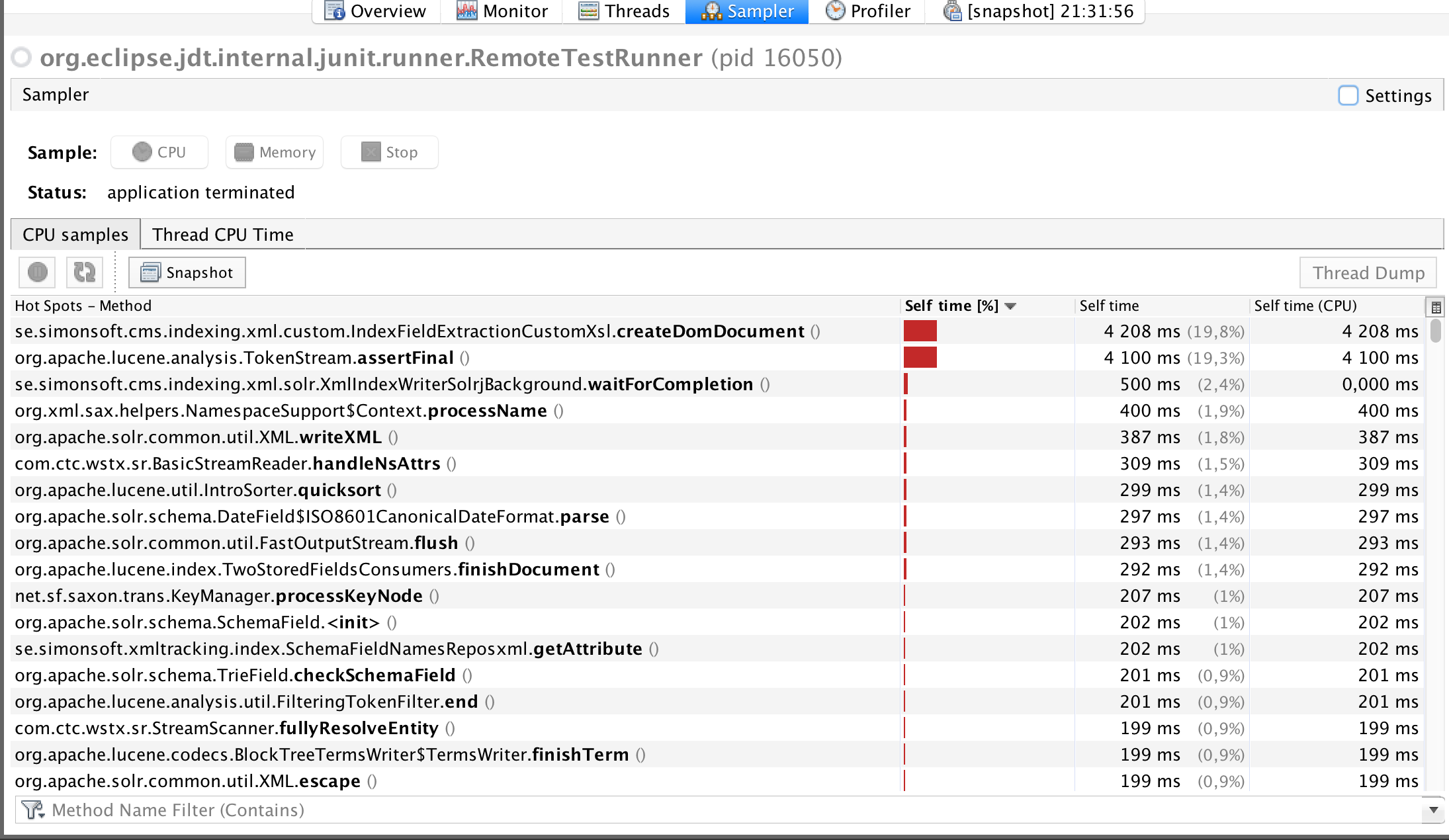
Saxon 9.6: The method createDomDocument seems to need some attention (my code). Total execution time 16s.
-
Saxon 9.7: 3 Saxon methods shows up at the top. Total execution time 93s.
Perhaps provides some indication until I manage to isolate a package.
Thanks!
Updated by Thomas Åkesson about 8 years ago
- File Screen Shot 2016-09-08 at 21.35.41.png Screen Shot 2016-09-08 at 21.35.41.png added
- File Screen Shot 2016-09-08 at 21.32.12.png Screen Shot 2016-09-08 at 21.32.12.png added
The screenshots mentioned in previous post.
Updated by Michael Kay about 8 years ago
The 9.7 performance seems to be dominated by sorting. A major objective for the optimizer is to eliminate the need to sort nodes into document order. Perhaps something has changed that means that in your particular case this isn't working.
The very intense hotspot on TinyAttributeImpl.getSequenceNumber() looks very startling, as this should be a pretty cheap method; but I've often seen JvisualVM samples over-represent one method like this, and the reasons are well documented. The method will be called in the course of sorting attribute nodes into document order and I think there's strong evidence here that such sorting is a dominant factor.
As for compile-time, we are aware that there has been regression in compile time, and are addressing it. We did a lot of work on one particular use case involving very large monolithic templates (see https://saxonica.plan.io/issues/2707). We've published some ideas for the way forward at http://dev.saxonica.com/blog/mike/2016/06/improving-compile-time-performance.html
Updated by Thomas Åkesson about 8 years ago
- File SaxonTransformerDomTraversalPerformanceTest.java SaxonTransformerDomTraversalPerformanceTest.java added
- File identity.xsl identity.xsl added
I have reproduced in an isolated class. We are traversing a DOM and executing multiple transforms with different starting context nodes. I simplified the example by stupidly transforming on every node.
I am not attaching any XML file. I believe any sizable XML file should work.
Should be possible to execute using the main method after adjusting paths. I execute with JUnit but that code path requires the package layout.
Approximate timings on my machine with an 800kB XML file:
-
Saxon 9.6: 16s
-
Saxon 9.7: 85s
Please adjust the issue title if possible.
Thanks!
Updated by Michael Kay about 8 years ago
For 9.6 I'm getting
Transformations: 48221
Transformations took: 20123 ms.
For 9.7 I'm getting
Transformations: 48221
Transformations took: 77071 ms.
Updated by Michael Kay about 8 years ago
If I cut out the xsl:strip-space I get
9.6:
Transformations: 48221
Transformations took: 1637 ms.
9.7:
Transformations: 48221
Transformations took: 1524 ms.
So xsl:strip-space is dramatically increasing the cost, and the effect is worse with 9.7.
Because you're supplying the input as a pre-built tree rather than as a stream source to be parsed, space stripping isn't happing inline with parsing, instead a virtual space-stripped tree is created in which whitespace nodes are skipped during navigation. I knew this was expensive but I didn't realise how much more expensive, and I don't know why it's got worse.
Note: despite what you say in your message, I don't think there is any DOM processing in this application. It's all based on Saxon TinyTrees.
Updated by Michael Kay about 8 years ago
I found one possible source of inefficiency: when testing whether an element is in the set of space-preserving/space-stripping elements, a hashcode is computed for the element's expanded name, despite the fact that there are no space-stripping rules that depend on the element name. I removed this from both the 9.6 and 9.7 paths but it only made a tiny difference.
Another similar source of inefficiency is that we aren't using element name fingerprints when looking for matching template rules (because a virtual SpaceStrippedNode is not treated as a FingerprintedNode). Indeed, there are no template rules with name-based patterns, so we could skip this search. But I tried that on the 9.7 branch, and again the saving is only modest (reduces the time to 74623ms).
Updated by Michael Kay about 8 years ago
JVisualVM sampling on the 9.7 branch shows that a very large proportion of the time is spent in a routine SpaceStrippedDocument.findPreserveSpace() which scans the document looking for xml:space attributes. In theory this is done once at the beginning of the transformation; if no xml:space attributes are found (as in this case) this avoids the need to subsequently check each whitespace text node as it is encountered to see whether it has xml:space on an ancestor element.
The 9.6 code is also calling this routine, but I think it is calling it less often, and this accounts for much of the regression.
In fact I think in 9.7 the method is called thrice per transformation, once during the call on "setInitialContextNode()" and twice during the call on transform(). This reflects the XSLT 3.0 separation between the global context item and the initial match selection, which can in principle be different things - we need to optimise for the case where they are the same.
Removing this triplication, by checking whether the node about to be processed is the same as the already-stripped global context item, brings the 9.7 time down to 26379ms and thus eliminates most of the regression.
Updated by Michael Kay about 8 years ago
Changing the application (in 9.7) to use an Xslt30Transformer and to invoke the transformation using transformer.applyTemplates() cuts the execution time dramatically, to 1314ms. Sadly this is a bug: the whitespace stripping is not happening at all on this path. I've logged that as a separate issue: https://saxonica.plan.io/issues/2931
Updated by Michael Kay about 8 years ago
I have now written a version of the SpaceStrippedDocument.findPreserveSpace() method (which searches the document for an xml:space="preserve" attribute) that is customised to the TinyTree - because the TinyTree holds all attributes in a single array this can be done very quickly, though it is probably especially fast in my case because I'm searching a document with many elements but very few attributes. This brings the 9.7 transformation time down to 1500ms, which is actually better than the measurement that did no space stripping at all.
Problem solved, I think.
Updated by Thomas Åkesson about 8 years ago
Note: despite what you say in your message, I don't think there is any DOM processing in this application. It's all based on Saxon TinyTrees.
Yes, I should have said: "We are traversing a Tree and executing multiple transforms with different starting context nodes."
In the isolated example there is no DOM code. In the integration test which I sampled (screenshots) there are some small pieces of DOM code.
Thanks for actively investigating.
I can reproduce your finding that removing xsl:strip-space in the test case dramatically improves execution time.
Interestingly, the full integration test (which I sampled) does not have xsl:strip-space in any of the stylesheets. There might be something more at play that I have not yet isolated.
Is there a way for me to get a build with your space stripping improvement? Preferably via Maven if you publish snapshots.
Updated by Michael Kay about 8 years ago
- Subject changed from Performance regression for extension functions in 9.7 to Performance regression for whitespace stripping in 9.7
- Category set to Performance
- Status changed from New to Resolved
- Assignee set to Michael Kay
- Applies to branch 9.8 added
- Fix Committed on Branch 9.7, 9.8 added
Updated by Thomas Åkesson about 8 years ago
- File namespace-unused.xsl namespace-unused.xsl added
Thanks for the build. I can confirm that it resolves the performance issue isolated above.
Unfortunately, I am still seeing the regression in my integration tests. Sampling the jvm shows high activity in Saxon but difficult to draw conclusions.
Managed to isolate to a quite experimental template that attempts to determine unused namespaces. I am sure there are better ways to achieve the same result (suggestions welcome) but there is also a significant difference btw Saxon 9.6 and 9.7 that might be interesting to look at.
Attaching a stylesheet that can be executed with the above Java code. Might need to declare a couple of namespaces in the XML.
Updated by Michael Kay about 8 years ago
- Status changed from Resolved to In Progress
Updated by Michael Kay about 8 years ago
OK, I'm seeing a time of 30907ms for 9.7 compared with 2180ms for 9.6.
Updated by Michael Kay about 8 years ago
9.7 is spending its time sorting nodes into document order. Specifically it is sorting the result of the key() function.
It seems that neither 9.6 nor 9.7 attempts to avoid this sort on the grounds that we are only testing for the existence of the result, we're not actually processing the results. It would be very easy to add this optimization.
But there is an optimization present in both releases that attempts to avoid the sort in the case where the second argument to key() is a single atomic value (because the nodes in the index are then already in sorted order). The exact way we test for this condition has changed between 9.6 and 9.7, and 9.7 is not taking the fast path. This will affect any use of xsl:key where there are large numbers of nodes with the same key value.
The changed code in the key() function is apparently due to the introduction of support for composite keys in 9.7.
Updated by Michael Kay about 8 years ago
A couple of observations:
(a) On the key() function, in 9.6 Saxon was taking the "fast path" (no sorting) when the static cardinality of the key expression is zero-or-one. In 9.7 it is taking this path based on the actual value. In principle this is better, since the actual value may be a singleton even if the static cardinality allows multiple values. The problem is that the "value" passed to the function is lazily evaluated, so its cardinality is not known.
(b) It seems that on a system function call in 9.7, we are unconditionally doing lazy evaluation of the arguments. There has been a significant change here(mainly caused by the need to improve support for higher order functions); previously each system function decided for itself how its arguments should be evaluated, rather than leaving it to the general-purpose function calling mechanism. But doing lazy evaluation of very simple arguments like a literal or a variable reference is pointless and only adds overhead.
Updated by Michael Kay about 8 years ago
I'm testing a new approach in the key() function: instead of doing a sort when there are multiple key values, we take the sequences returned from each key value (each of which is in document order) and apply the union operator to combine them. Merging two sequences that are in document order should be faster than concatenating them and then sorting.
First attempt at this reduces the 9.7 time to 1506ms.
Updated by Michael Kay about 8 years ago
- Status changed from In Progress to Resolved
The new logic in the key() function seems sound. I've committed this change on 9.7 and 9.8.
With this change, there is no point in exists()/empty() telling key() not to sort, because it isn't going to do so anyway.
For 9.8 I've added logic to SystemFunctionCall that avoids lazy evaluation of the argument if it's a literal or variable reference.
Updated by Michael Kay about 8 years ago
There was a typo in the 9.7 version of the patch to SelectedElementsSpaceStrippingRule, which is now corrected.
 Updated by O'Neil Delpratt about 8 years ago
Updated by O'Neil Delpratt about 8 years ago
- Status changed from Resolved to Closed
- % Done changed from 0 to 100
- Fixed in Maintenance Release 9.7.0.10 added
Bug fix applied in the Saxon 9.7.0.10 maintenance release
Updated by O'Neil Delpratt over 7 years ago
- Applies to branch deleted (
9.8) - Fix Committed on Branch trunk added
- Fix Committed on Branch deleted (
9.8)
Please register to edit this issue